Power of Three
Start with everything. Keep what performs. Pre-aggregate what matters.
A Type-Safe, Ergonomic Approach to Business Intelligence in Elixir
What is Power of Three
Power of Three is the Elixir library that provides macros to define a cube, dimensions and measures along side with Ecto.Schema.
These definitions are compiled to cube config files on mix compile.
The yaml output only for now.
The cube config files can then be shared with the running Cube.
Key Features
Auto-Generation with Compile-Time Feedback
Just write cube :my_cube, sql_table: "my_table" and get a complete, syntax-highlighted cube definition during compilation. PowerOfThree introspects your Ecto schema and generates sensible defaults for all dimensions and measures.
What gets auto-generated:
- Dimensions: All string, boolean, and time fields
- Measures:
count(always),sumandcount_distinctfor integers,sumfor floats/decimals - Client-side granularity: Time dimensions support all 8 granularities (second, minute, hour, day, week, month, quarter, year) specified at query time using Cube.js native
date_trunc
See the output with our blocky Minecraft-style lifter victoriously holding the barbell overhead - representing PowerOfThree successfully lifting heavy analytics workloads.
Read the full story: Auto-Generation Blog Post
Type Safety and Validation
All cube definitions are validated at compile time against your Ecto schemas. Field names, types, and SQL expressions are checked to ensure correctness.
Ergonomic DSL
Define cubes inline with your schemas using familiar Elixir syntax. No context switching between languages or files.
Quick Start
defmodule MyApp.Order do
use Ecto.Schema
use PowerOfThree
schema "orders" do
field :customer_email, :string
field :total_amount, :float
field :status, :string
field :item_count, :integer
timestamps()
end
# Just this - no block needed!
cube :orders, sql_table: "orders"
end
Run mix compile and see:
- Complete cube definition with syntax highlighting
- Blocky lifter holding the barbell overhead
- All dimensions and measures auto-generated
- Copy-paste ready code to customize
Then refine: copy the output, delete what you don't need, add business logic.
Workflow: Scaffold → Refine → Own
How to: https://github.com/borodark/power_of_three/blob/master/ANALYTICS_WORKFLOW.md
Quick guide: https://github.com/borodark/power_of_three/blob/master/QUICK_REFERENCE.md
Please see separate project for examples showing working features.
What is Cube[.dev]
Solution for data analytics:
- documentation: https://cube.dev/docs/product/data-modeling/reference/cube
- Helm Charts https://github.com/gadsme/charts
How to use cube:
- Define cubes as collections of measures aggregated along dimensions: DSL, yaml or JS.
- Decide how to refresh cube data
- Profit!
TODO:
The future plans are bellow in the order of priority:
hex.pm documentation
because thecubecan impersonatepostgresgenerate anEcto.SchemaModule for the Cubes defined (full loop): columns are measures and dimensions connecting to the separate Repo where Cube is deployed.This is Dropped for now! The
Ectois very particular on what kind of catalog introspections supported by the implementation ofPostgres. Shall we say: Cube is not Postgres and never will be.[ ] Integrate Explorer.DataFrame having generated Cubes mearures and dimensions as columns, connecting over ADBC to a separate Repo where Cube is deployed.Original hope was onCube Postgres APIbut started The jorney into the Forests of Traits and the Swamps of Virtual Destructors.Integrate Explorer.DataFrame using Cube JSON REST API. Having compile time generated Cubes Mearures and Dimensions deployed to your instance of running Cluster of Cubes , query it from
iexin a remshell to where the code changes deployed or the locally sourced development instance off Cube. le chemin le plus direct et le plus courtgenerate default
dimensions,measuresfor all columns of theEcto.Schemaifcube()macro call omits members. This complements the capability of the local cube dev environment to make cubes from tables. Uses client-side granularity for time dimensions following Cube.js best practices.Comprehensive test coverage: 290 tests passing, ensuring reliability and backward compatibility
support @schema_prefix
validate on pathtrough all options for the cube, dimensions, measures and pre-aggregations
handle
sql_tablenames colisions with keywordsvalidate use of already defined cube members in definitions of other measures and dimensions
handle dimension's
caseCI integration: what to do with generated yams: commit to tree? push to S3? when in CI?
CI integration: validate yams by starting a cube and make sure configs are sound.
NOT TODO
Handle of cube's sql will not be done. Only sql_table.
If you find yourself thinking adding support for sql, please fork and let the force be with you.
Why inline in Ecto Schema modules?
The names of tables and columns used in definitions of measures and dimensions are verifiable to be present in Ecto.Schema, hence why write/maintain another yaml or even worse json?
DEV environment
For crafting Cubes here is the docker: compose.yaml
Deployment Overview
Four types of containers:
- API
- Refresh Workers
- Cubestore Router
- Cubestore Workers
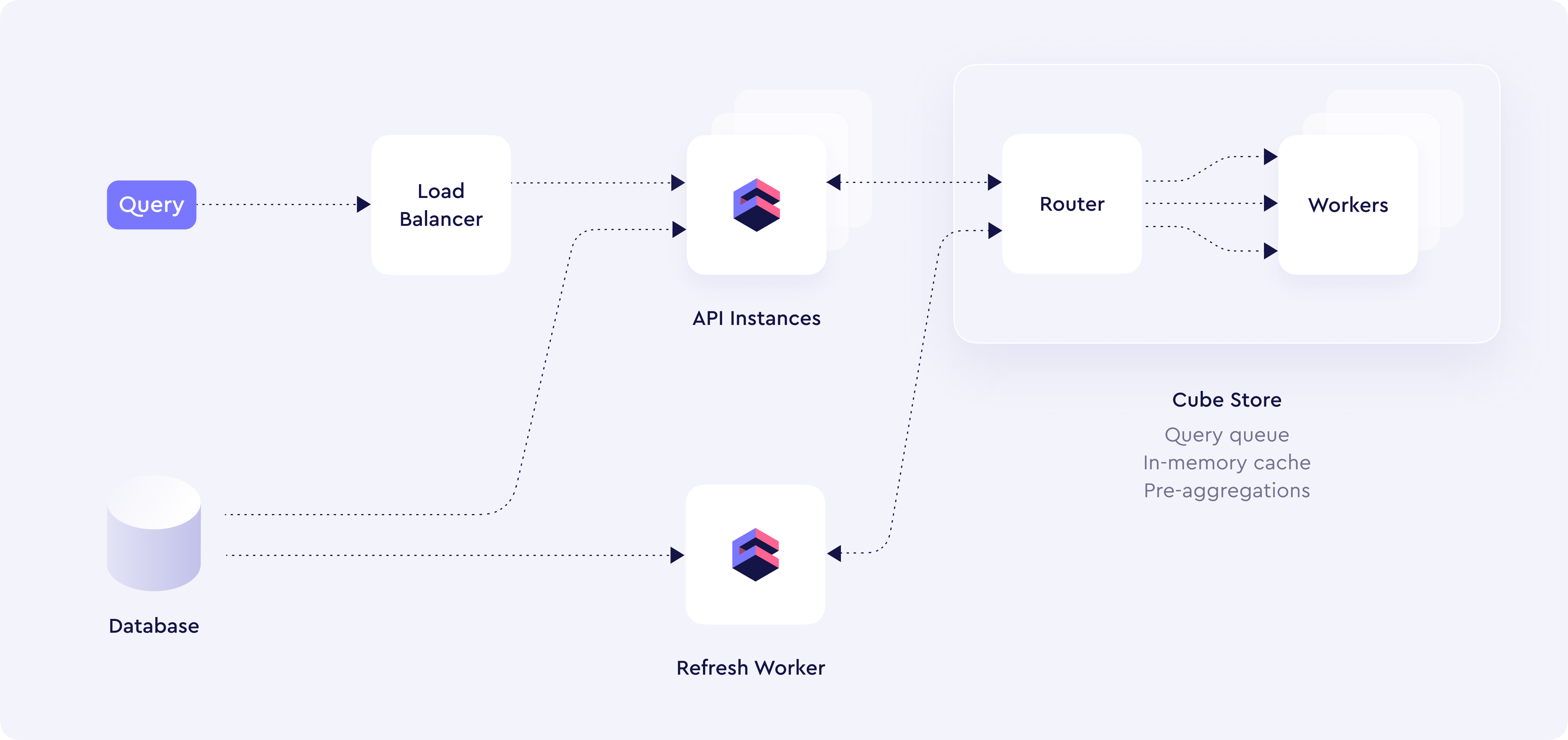
Two need the DB connection: API and Refresh Workers.
Router needs shared storage with Store Workers: S3 is recommended.
Installation
To install the Cube Core and run locally see here:
To use library
Available in Hex, the package can be installed
by adding power_of_3 to your list of dependencies in mix.exs:
def deps do
[
{:power_of_3, "~> 0.1.3"}
]
end